.png)
February 25, 2025
.webp)
In today's data-driven epoch, as we deftly dance on the digital tapestry weaved by countless bytes, there stands a silent guardian: Data Anonymization. But what is this silent protector, and why is it of such monumental importance? Let's journey through its labyrinth to understand its essence and its undeniable significance.
What Is Data Anonymization
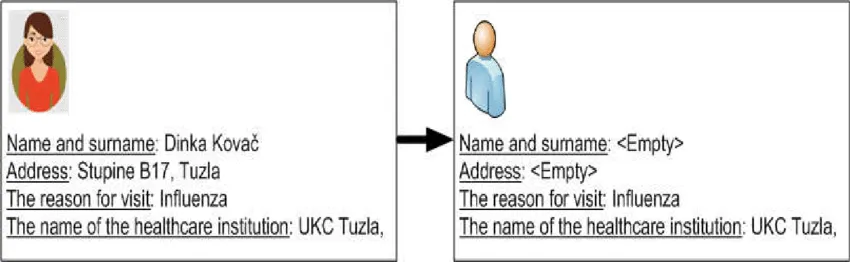
Data anonymization is the process of protecting private or sensitive information by erasing or encrypting identifiers that connect an individual to stored data. For example, you can run Personally Identifiable Information (PII) such as names, social security numbers, and addresses through a data anonymization process that retains the data but keeps the source anonymous.
However, even when you clear data of identifiers, attackers can use de-anonymization methods to retrace the data anonymization process. Since data usually passes through multiple sources—some available to the public—de-anonymization techniques can cross-reference the sources and reveal personal information.
The General Data Protection Regulation (GDPR) outlines a specific set of rules that protect user data and create transparency. While the GDPR is strict, it permits companies to collect anonymized data without consent, use it for any purpose, and store it for an indefinite time—as long as companies remove all identifiers from the data.
But why is data anonymization so essential?
- Legal Compliance: As data privacy regulations become more stringent, non-compliance can lead to hefty fines and damage to your organization's reputation. Data anonymization helps you meet these legal requirements without sacrificing the utility of your data.
- Enhanced Security: By anonymizing data, you minimize the risk of a data breach. Even if your data is compromised, it won't reveal sensitive details about individuals, reducing the potential harm.
- Ethical Considerations: Respecting individuals' privacy rights is not just a legal obligation; it's an ethical one. Data anonymization ensures that you handle data responsibly and ethically.
Data Anonymization Techniques
- Data masking—hiding data with altered values. You can create a mirror version of a database and apply modification techniques such as character shuffling, encryption, and word or character substitution. For example, you can replace a value character with a symbol such as “*” or “x”. Data masking makes reverse engineering or detection impossible.
- Pseudonymization—a data management and de-identification method that replaces private identifiers with fake identifiers or pseudonyms, for example replacing the identifier “John Smith” with “Mark Spencer”. Pseudonymization preserves statistical accuracy and data integrity, allowing the modified data to be used for training, development, testing, and analytics while protecting data privacy.
- Generalization—deliberately removes some of the data to make it less identifiable. Data can be modified into a set of ranges or a broad area with appropriate boundaries. You can remove the house number in an address, but make sure you don’t remove the road name. The purpose is to eliminate some of the identifiers while retaining a measure of data accuracy.
- Data swapping—also known as shuffling and permutation, a technique used to rearrange the dataset attribute values so they don’t correspond with the original records. Swapping attributes (columns) that contain identifiers values such as date of birth, for example, may have more impact on anonymization than membership type values.
- Data perturbation—modifies the original dataset slightly by applying techniques that round numbers and add random noise. The range of values needs to be in proportion to the perturbation. A small base may lead to weak anonymization while a large base can reduce the utility of the dataset. For example, you can use a base of 5 for rounding values like age or house number because it’s proportional to the original value. You can multiply a house number by 15 and the value may retain its credence. However, using higher bases like 15 can make the age values seem fake.
- Synthetic data—algorithmically manufactured information that has no connection to real events. Synthetic data is used to create artificial datasets instead of altering the original dataset or using it as is and risking privacy and security. The process involves creating statistical models based on patterns found in the original dataset. You can use standard deviations, medians, linear regression or other statistical techniques to generate the synthetic data.
Challenges of Data Anonymization
While data anonymization is crucial, it's not without its challenges:
- Data Utility vs. Privacy: Striking the right balance between preserving data utility and ensuring privacy can be challenging. Aggressive anonymization can render data less useful for analysis.
- De-Anonymization Risks: As data becomes more interconnected across various sources, the risk of de-anonymization increases. Attackers may use external data to re-identify individuals.
- Maintaining Data Quality: Anonymizing data can introduce errors or inaccuracies. Ensuring the quality and integrity of the data after anonymization is a complex task.
- Changing Regulations: Data protection laws are evolving. Staying compliant with ever-changing regulations while anonymizing data requires ongoing effort and adaptation.
Real-world Applications of Data Anonymization
Data anonymization finds application across various industries and sectors worldwide:
- Healthcare: In medical research, sensitive patient data needs to be anonymized to comply with regulations like HIPAA. Researchers can still analyze patterns and trends without compromising patient privacy.
- Finance: Financial institutions use data anonymization to protect customer information while conducting fraud detection and market analysis. It enables them to identify patterns without exposing individual identities.
- Marketing: Marketers can utilize anonymized customer data to gain insights into consumer behavior, preferences, and trends without infringing on privacy. This aids in targeted advertising campaigns.
- Education: Anonymizing student data allows educational institutions to perform research and analyze educational trends while complying with student privacy laws like FERPA in the United States.
- Government and Census: Governments use data anonymization techniques to publish census and demographic data. It helps in resource allocation, urban planning, and policy development while protecting individual privacy.
Indika AI: Your Trusted Partner in Data Anonymization
At Indika AI, we understand that your data is your most valuable asset. That's why we offer state-of-the-art data anonymization services designed to meet your unique needs. Here's how we can help you:
- Advanced Anonymization Techniques: Our team of experts utilizes cutting-edge techniques to transform your data, preserving its utility while safeguarding privacy. We tailor our methods to your specific dataset and industry, ensuring compliance with relevant regulations.
- Customized Solutions: We understand that every dataset is different. Our solutions are not one-size-fits-all; they are tailored to your data, business objectives, and compliance requirements.
- Scalability: Whether you have a small dataset or petabytes of information, Indika AI has the scalability to handle your needs. Our robust infrastructure can accommodate data of any size and complexity.
- Security at the Core: Security is at the heart of everything we do. Your data is handled with the utmost care and protected using the latest security protocols to ensure confidentiality and integrity.
- Comprehensive Compliance: We stay up-to-date with the ever-evolving landscape of data protection laws. Our services are designed to keep you compliant with the latest regulations, providing you with peace of mind.
The Indika AI Difference
What sets us apart at Indika AI is our commitment to not only meeting but exceeding your expectations. We combine cutting-edge technology with a human touch to deliver the best data anonymization services in the industry.
Our passion for data privacy and our unwavering dedication to our clients make us the ultimate choice for your data anonymization needs. When you partner with Indika AI, you're not just getting a service; you're gaining a trusted ally in the battle for data privacy.
In an age where data is king, protecting the privacy and security of individuals and organizations is non-negotiable. Data anonymization is the key to unlocking the potential of your data while staying compliant with the law and maintaining ethical standards.
At Indika AI, we take pride in being at the forefront of data anonymization technology. Our commitment to excellence, customized solutions, and unwavering dedication to your data's security make us the ideal partner for your data anonymization journey.
Contact us today to learn more about how Indika AI can help you safeguard your data and achieve your business goals while maintaining the highest standards of privacy and compliance. Together, we can make the digital world safer and more responsible for everyone.


