.png)
February 25, 2025
.webp)
What Is Retrieval-Augmented Generation (RAG)?
Generative AI, particularly in text-based applications, thrives on its capacity to produce clear and comprehensive responses. This is enabled by training the AI on a vast array of data points. The advantage of this approach is that the text generated is typically user-friendly and answers a wide range of questions, known as prompts, with relevant information.
However, there are limitations. The data used for training these AI models, often large language models (LLMs), might not be up-to-date. This means that the AI's knowledge could be weeks, months, or even years old. In the context of a corporate AI chatbot, this limitation becomes more pronounced as the AI may lack specific and current information about the company's products or services. This gap in knowledge can sometimes lead to responses that are not accurate, potentially diminishing user trust in the AI technology.
When you build your application on top of a base large language model (LLM) like GPT or Llama, it's important to understand its capabilities and limitations. If you ask a question to such a model, you might soon notice that these models often lack context or have very limited understanding of how things work. Moreover, even if they had a grasp on current events or specific information, it would likely be outdated, perhaps as far back as September 2021. This is a key consideration when relying on these AI models for up-to-date information or context-specific inquiries.
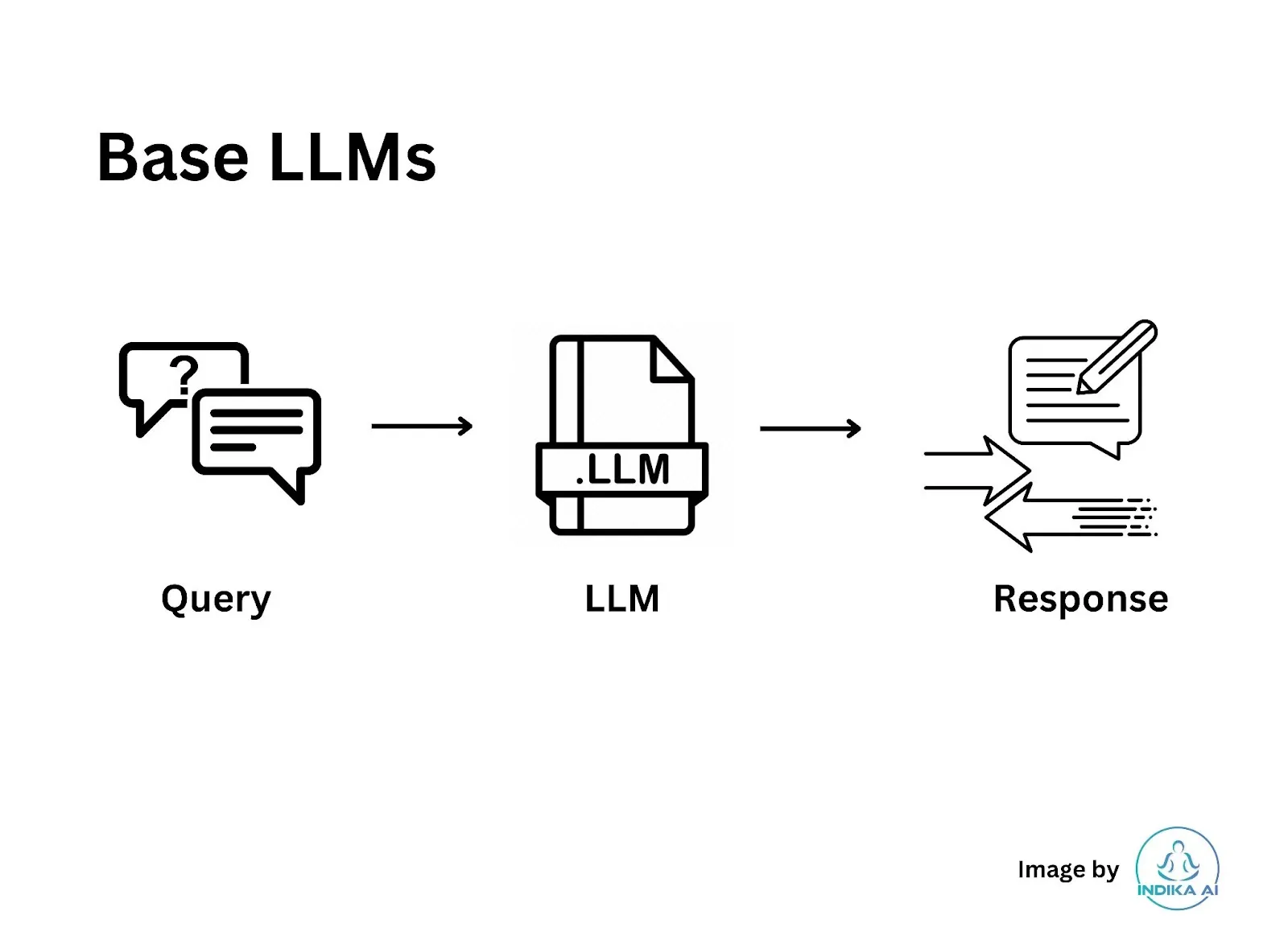
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an advanced technique in the field of generative AI that enhances the capabilities of large language models (LLMs). The key feature of RAG is its ability to supplement the output of an LLM with specific, up-to-date information without altering the core model. This targeted information can be more current than what's contained in the LLM, and can be tailored to specific industries or organizations.
The primary advantage of RAG is that it enables generative AI systems to provide answers that are more contextually relevant and based on the most recent data. This approach is particularly valuable in scenarios where the latest information is crucial or where specific industry knowledge is required.
RAG gained prominence in the AI community following the publication of the paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" in 2020. Authored by Patrick Lewis and his team at Facebook AI Research, this paper laid the groundwork for the concept. Since then, RAG has been widely adopted and explored by both academic and industrial researchers, seen as a method to significantly enhance the utility and accuracy of generative AI systems.
Benefits of Retrieval Augmented Generation (RAG)
- Enhanced LLM Memory: One of the primary benefits of RAG is its ability to expand the memory capacity of LLMs. Traditional LLMs rely on what's known as "Parametric memory," which is limited. RAG introduces "Non-Parametric memory" by accessing external knowledge sources. This expansion of the knowledge base allows LLMs to provide more comprehensive and accurate responses.
- Improved Contextualization: RAG enhances the ability of LLMs to understand context by retrieving and incorporating relevant contextual documents. This allows the model to generate responses that are more closely aligned with the specific context of a user's input, leading to more accurate and contextually appropriate outputs.
- Updatable Memory: A key feature of RAG is its capacity to incorporate real-time updates and new information sources without the need for extensive model retraining. This keeps the external knowledge base up-to-date, ensuring that the responses generated by the LLM are always based on the latest and most relevant information.
- Source Citations: Models equipped with RAG can provide citations for their responses, which enhances their transparency and credibility. By giving users access to the sources that inform the LLM’s responses, RAG promotes greater trust in AI-generated content.
- Reduced Hallucinations: Studies have indicated that RAG models exhibit fewer instances of hallucinations and demonstrate higher response accuracy. They are also less likely to inadvertently reveal sensitive information. This reduction in hallucinations and increase in accuracy make RAG models more reliable for content generation.
These advantages collectively position RAG as a transformative approach in Natural Language Processing (NLP), overcoming the inherent limitations of traditional language models and significantly enhancing the capabilities of AI-powered applications.
Retrieval-Augmented Generation Explained
Retrieval-Augmented Generation (RAG) can be understood through a practical example, such as a sports league wanting to provide real-time, detailed information to fans and media through a chat system. Here's how RAG enhances this process:
- Limitations of Generalized LLMs: A standard large language model (LLM) can answer generic questions about sports history, rules, or describe a team’s stadium. However, it falls short in providing current information like recent game results or updates on an athlete’s injury. This is because an LLM's knowledge is static, and retraining it frequently to keep it up-to-date is not feasible due to the significant computational resources required.
- Leveraging RAG for Current Information: In this scenario, the sports league has access to various dynamic information sources: databases, data warehouses, player bios, and news feeds with detailed game analyses. RAG allows the AI to ingest and utilize this diverse and up-to-date information, thereby enabling the chat system to provide more timely, contextually relevant, and accurate responses.
- Enhancing LLMs with RAG: Essentially, RAG acts as a bridge that connects LLMs with additional data sources. This connection is crucial because it doesn't require retraining the LLM. Instead, RAG builds knowledge repositories from the organization’s data, which can be continually updated, allowing the AI to provide responses that are both timely and contextually appropriate.
- Broad Applications: Chatbots and other conversational systems using natural language processing (NLP) can greatly benefit from the integration of RAG. This approach enhances the quality of responses in generative AI applications, making them more useful for a variety of purposes.
- Technological Requirements for Implementing RAG: To effectively implement RAG, specific technologies are needed. For instance, vector databases are crucial as they enable the rapid coding of new data and facilitate searches against this data, which can then be fed into the LLM. This technology ensures that the RAG system can efficiently retrieve and utilize the most relevant and current information.
In summary, RAG represents a significant advancement in the field of AI, particularly for applications that require up-to-date and context-specific information. Its ability to enhance LLMs without the need for constant retraining makes it a valuable tool in developing more responsive and accurate AI-driven chat and information systems.
How Does Retrieval-Augmented Generation Work?
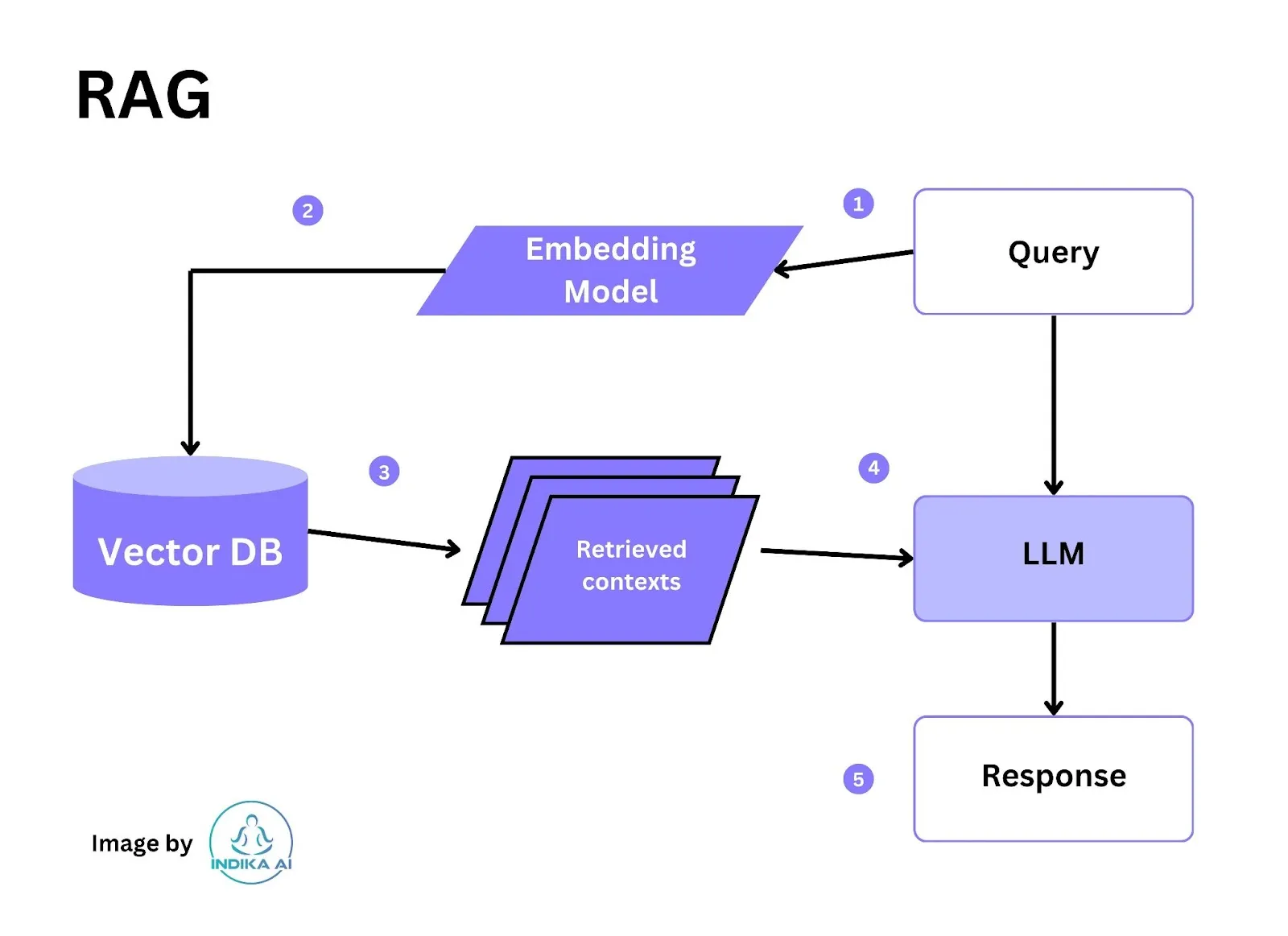
Consider all the information that an organization has—the structured databases, the unstructured PDFs and other documents, the blogs, the news feeds, the chat transcripts from past customer service sessions. In RAG, this vast quantity of dynamic data is translated into a common format and stored in a knowledge library that’s accessible to the generative AI system.
The data in that knowledge library is then processed into numerical representations using a special type of algorithm called an embedded language model and stored in a vector database, which can be quickly searched and used to retrieve the correct contextual information.
RAG and Large Language Models (LLMs)
Now, say an end user sends the generative AI system a specific prompt, for example, “Where will tonight’s game be played, who are the starting players, and what are reporters saying about the matchup?” The query is transformed into a vector and used to query the vector database, which retrieves information relevant to that question’s context. That contextual information plus the original prompt are then fed into the LLM, which generates a text response based on both its somewhat out-of-date generalized knowledge and the extremely timely contextual information.
Interestingly, while the process of training the generalized LLM is time-consuming and costly, updates to the RAG model are just the opposite. New data can be loaded into the embedded language model and translated into vectors on a continuous, incremental basis. In fact, the answers from the entire generative AI system can be fed back into the RAG model, improving its performance and accuracy, because, in effect, it knows how it has already answered a similar question.
An additional benefit of RAG is that by using the vector database, the generative AI can provide the specific source of data cited in its answer—something LLMs can’t do. Therefore, if there’s an inaccuracy in the generative AI’s output, the document that contains that erroneous information can be quickly identified and corrected, and then the corrected information can be fed into the vector database.
In short, RAG provides timeliness, context, and accuracy grounded in evidence to generative AI, going beyond what the LLM itself can provide.
Retrieval-Augmented Generation vs. Semantic Search
RAG isn’t the only technique used to improve the accuracy of LLM-based generative AI. Another technique is semantic search, which helps the AI system narrow down the meaning of a query by seeking deep understanding of the specific words and phrases in the prompt.
Traditional search is focused on keywords. For example, a basic query asking about the tree species native to France might search the AI system’s database using “trees” and “France” as keywords and find data that contains both keywords—but the system might not truly comprehend the meaning of trees in France and therefore may retrieve too much information, too little, or even the wrong information. That keyword-based search might also miss information because the keyword search is too literal: The trees native to Normandy might be missed, even though they’re in France, because that keyword was missing.
Semantic search goes beyond keyword search by determining the meaning of questions and source documents and using that meaning to retrieve more accurate results. Semantic search is an integral part of RAG.
The Future of RAGs and LLMs
The evolution of Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs) is poised for exciting developments:
- Advancements in Retrieval Mechanisms: The future of RAG will witness refinements in retrieval mechanisms. These enhancements will focus on improving the precision and efficiency of document retrieval, ensuring that LLMs access the most relevant information quickly. Advanced algorithms and AI techniques will play a pivotal role in this evolution.
- Integration with Multimodal AI: The synergy between RAG and multimodal AI, which combines text with other data types like images and videos, holds immense promise. Future RAG models will seamlessly incorporate multimodal data to provide richer and more contextually aware responses. This will open doors to innovative applications like content generation, recommendation systems, and virtual assistants.
- RAG in Industry-Specific Applications: As RAG matures, it will find its way into industry-specific applications. Healthcare, law, finance, and education sectors will harness RAG-powered LLMs for specialized tasks. For example, in healthcare, RAG models will aid in diagnosing medical conditions by instantly retrieving the latest clinical guidelines and research papers, ensuring doctors have access to the most current information.
- Ongoing Research and Innovation in RAG: The future of RAG is marked by relentless research and innovation. AI researchers will continue to push the boundaries of what RAG can achieve, exploring novel architectures, training methodologies, and applications. This ongoing pursuit of excellence will result in more accurate, efficient, and versatile RAG models.
- LLMs with Enhanced Retrieval Capabilities: LLMs will evolve to possess enhanced retrieval capabilities as a core feature. They will seamlessly integrate retrieval and generation components, making them more efficient at accessing external knowledge sources. This integration will lead to LLMs that are proficient in understanding context and excel in providing context-aware responses.
Retrieval-Augmented Generation FAQs
Is RAG the same as generative AI?
No. Retrieval-augmented generation is a technique that can provide more accurate results to queries than a generative large language model on its own because RAG uses knowledge external to data already contained in the LLM.
What type of information is used in RAG?
RAG can incorporate data from many sources, such as relational databases, unstructured document repositories, internet data streams, media news feeds, audio transcripts, and transaction logs.
How does generative AI use RAG?
Data from enterprise data sources is embedded into a knowledge repository and then converted to vectors, which are stored in a vector database. When an end user makes a query, the vector database retrieves relevant contextual information. This contextual information, along with the query, is sent to the large language model, which uses the context to create a more timely, accurate, and contextual response.
Can a RAG cite references for the data it retrieves?
Yes. The vector databases and knowledge repositories used by RAG contain specific information about the sources of information. This means that sources can be cited, and if there’s an error in one of those sources it can be quickly corrected or deleted so that subsequent queries won’t return that incorrect information.


