.png)
February 25, 2025
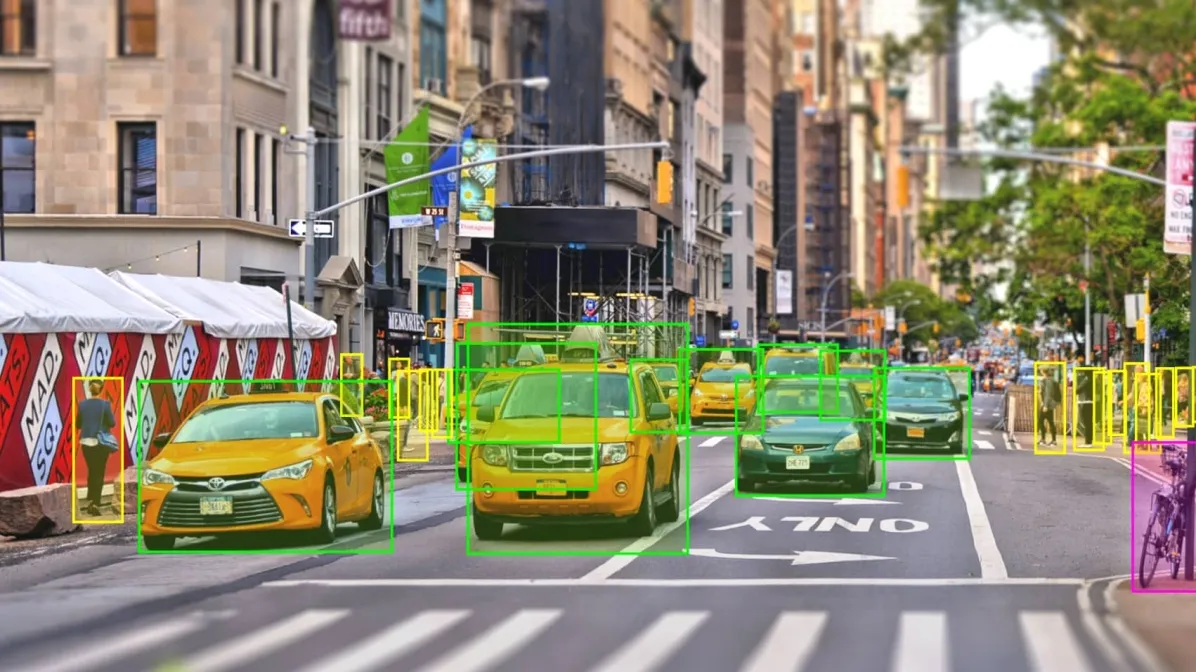
In our transformative digital age, where data has become the cornerstone of technological progress, understanding the intricacies behind it is not just beneficial – it's essential. Drawing a parallel, imagine crude oil. To fuel machines, it needs refining. Similarly, for data to fuel our sophisticated algorithms, it requires a unique refinement process: data annotation. Now, let’s unravel this fascinating procedure that stands as the backbone of many innovations today.
What is Data Annotation?
Data annotation is the process of adding labels or tags to data to help computers understand and learn from it. It's like giving information to a computer by adding notes or markings on the data. These labels can describe things like objects in images, words in text, or other details in data. Data annotation is important for training machine learning models and making them better at tasks like image recognition, language translation, and more.
At its core, data annotation is akin to tagging or labelling raw data to make it understandable and actionable. Picture this: You have a diverse collection of photographs – spanning picturesque landscapes, bustling urban centres, serene countryside, and intricate close-ups. If you were to attach descriptive labels to each, you'd be delving into the realm of data annotation. In the digital universe, this process becomes paramount, especially when it comes to training intricate machine learning models. By ensuring these models have access to labelled data, we pave the way for accurate recognition and processing.
The Riveting Journey of Data Annotation
From Humble Beginnings to Modern Marvels
Data annotation might feel like a child of the digital age, but its roots stretch back further. Tracing its origins, we find that as early as the late 20th century, visionaries and pioneers recognized the indispensable value of labelled data. These early iterations laid the foundation for algorithms capable of discerning patterns.
Fast-forward to the technological renaissance of the 21st century, the emergence of Artificial Intelligence (AI) and advanced machine learning technologies catapulted the need for annotated data to stratospheric levels. The race was on arming machines with a plethora of accurately labelled data to supercharge their learning and predictive capabilities.
The Imperative of Data Annotation
The Lifeblood of Machine Learning
Imagine trying to teach a child without examples or context. Difficult, right? Similarly, for machine algorithms to truly "learn", they require diverse and illustrative examples. These examples spring from the well of annotated data. Thus, the better our annotations, the more nuanced and astute our machines turn out.
The Pillar of Data Accuracy
In a world where misinformation spreads like wildfire, accuracy is the gold standard. Data annotation ensures that our data isn't just vast; it's precise, relevant, and reliable.
Crafting the Backbone for AI Training
Without an arsenal of accurately labelled data, AI models would be like ships without a compass. They might sail, but they'd need more direction. Data annotation provides this much-needed navigational aid, ensuring AI can interpret and act on information with finesse.
The Multifaceted World of Data Annotation
Image Annotation: Decoding the Visual
An age-old adage states, "A picture is worth a thousand words." Yet, a picture could be a meaningless amalgamation of pixels without proper annotation for machines. By meticulously labelling parts of an image, we empower machines to discern, recognize, and act on them. For instance, according to the Neural Information Processing Systems, image annotation has significantly improved the effectiveness of diagnostic radiology, a clear testament to its profound implications.
Text Annotation: Dissecting Words and Context
The beauty of language lies in its richness and ambiguity. Through text annotation, we give machines a lens to view and understand human language with all its nuances, metaphors, and intricacies.
Video Annotation: Sifting Through Moving Imagery
With the meteoric rise of video content, especially on platforms like YouTube (which, as of 2021, had 2.3 billion users worldwide according to Statista), understanding moving imagery becomes imperative. Video annotation involves labelling actions, objects, or sequences, allowing for dynamic data interpretation.
Audio Annotation: Fueling the Future of Voice and Sound Recognition
Audio annotation is a specific type of data annotation where you add labels or information to audio files. This process helps computers understand and work with audio data more effectively. For example, in speech recognition, audio annotation might involve marking the words spoken in a recording to train a machine learning model to transcribe speech accurately. Similarly, in audio classification tasks, you might label different sounds or events within an audio clip to teach a model to recognize and categorize them. Essentially, audio annotation makes it easier for computers to process and analyze audio information, improving their ability to understand and interpret sound.
The Intricate Dance of Data Annotation
The journey begins with raw data collection, sourced from myriad avenues, be it websites, sensors, or direct user inputs. Once amassed, the next step, often the most labour-intensive, is labelling. Whether through human expertise or AI tools, data gets tagged, categorized, and annotated. But the task doesn't end there. A rigorous verification stage ensures the data's integrity, highlighting the dedication to precision.
Technological Allies in Data Annotation
- The Human Touch : While automation sweeps across industries, specific nuances, subtleties, and intricacies of data annotation still lean on the irreplaceable human touch. A multitude of tools offer experts the luxury of manual annotation, ensuring the utmost quality.
- The Power of Automation : Yet, in a race against time, efficiency becomes king. Automated annotation tools, some harnessing the prowess of AI, have revolutionized the speed and scale at which data annotation occurs, making vast data lakes manageable
Programmatic labeling, also known as automated labeling or auto-labeling, is a process where you use software or algorithms to automatically generate labels or annotations for data. Instead of manually assigning labels to data points, you design rules or algorithms that can recognize and categorize the data automatically.
Programmatic labeling is often used in machine learning and data preprocessing tasks to save time and effort. For example, in image recognition, you might use computer vision algorithms to automatically label objects in images. In text analysis, natural language processing techniques can be employed to auto-label text documents based on their content.
The key advantage of programmatic labeling is its efficiency, as it can handle large volumes of data quickly. However, the accuracy of programmatic labeling depends on the quality of the algorithms and rules you create, and it may still require some manual oversight and validation to ensure correctness.
IndikaAI: Pioneering Data Annotation Solutions
IndikaAI excels in the world of data-focused AI. Their speciality? Perfectly blending top-notch tech tools with real human skills to refine large AI models. At its heart, IndikaAI isn’t just about high-tech solutions; it's about reshaping how businesses use AI to innovate and be more efficient.
What makes IndikaAI stand out is its all-encompassing strategy. While they craft tailored AI tools for many industries, they always underline the need for top-tier data. With a helping hand from their other product lines, they spotlight the crucial role people play in making sure this data is the best it can be. They're especially active in areas like healthcare, fintech, and online education. Here, they've proven they can tackle tough industry challenges with their unique AI tools. For anyone building AI systems, IndikaAI provides the sturdy data foundation they need to make those systems shine. In essence, IndikaAI is shaping the future of AI, one data point at a time.
Trials and Triumphs in Data Annotation
- Battling Ambiguity : One of the most formidable challenges is the inherent ambiguity in language and imagery. Assigning the correct label requires discernment, expertise, and sometimes, a dash of intuition.
- Scaling the Mountain : In our era, where every second, a staggering 1.7MB of data is created for every person on earth (as reported by DOMO in 2020), scaling data annotation efforts without diluting quality is a herculean task.
- Striking a Balance: Cost vs. Quality : Top-tier annotation demands top-tier expertise. And unsurprisingly, this expertise commands a price. Striking a balance between cost-effectiveness and unparalleled quality remains a tightrope act for many in the industry.
In the digital landscape we navigate today, data emerges as both a hurdle and a treasure trove. Just as we refine natural resources to energize our devices, data annotation serves to transform raw data into meaningful resources for our AI-powered era. Whether it's interpreting a simple picture or delving into the depth of human conversation, the meticulous nature and scope of data annotation are central to AI's effectiveness.
Challenges, from understanding vague contexts to managing vast volumes, are undeniable. Yet, entities like IndikaAI showcase the beauty of blending tech solutions with a human touch. As we edge closer to an AI-centric world, embracing and refining the art of data annotation will be paramount. Beyond its technicalities, it's evident: that data annotation is not just a mere step; it's the foundation of our tech-savvy future.


